Deep Learning para Detección de URL's Maliciosas (Phishing)
Proyecto desarrollado enfocando la ciberseguridad con el Deep Learning, para mayor información revisar mi directorio: https://github.com/Manuel-Flores-F/Phishing_Detect_NN.git
Resumen
Se ha puesto a pensar de que la forma más fácil y desconcertante de que una persona obtenga su información personal es que simplemente nos la pida. Y si nos sentimos en confianza con esa persona procedemos a brindarle esa información sin siquiera sospechar los motivos detrás de esa extraña solicitud. Esto es considerado un ataque de ingeniería.
Actualmente los estafadores usan mensajes de correo electrónico, mensajes de texto para engañar y lograr obtener su información personal y si el destinatario confía ( o mejor dicho, no desconfía) del emisor entonces podría ser victima del robo de su información sensible. Y con esa información brindada voluntariamente, podría ser victima de un robo de identidad.
Todos los días, los estafadores lanzan miles de ataques de phishing como estos, y suelen tener éxito. Es cierto preguntarse ¿Quien puede caer en estos trucos? pero la respuesta es mas seria de lo que se cree, el Internet Crime Complaint Center del FBI reportó que la gente perdió $30 millones de dólares en un año con esquemas de phishing.
Introducción
El propósito de este proyecto es construir un clasificador que pueda detectar URL maliciosas. Esto se logrará utilizando un enfoque de aprendizaje profundo.
Con un enfoque alternativo "Featureless Deep Learning", donde una capa de integración se encarga de derivar vectores de características de los datos sin procesar. Sin embargo, las desventajas de este enfoque son que se necesitan más data de entrenamiento y que la fase de entrenamiento requiera más tiempo.Enfoque Tradicional
Las investigaciones previamente realizadas se centraban en diferentes caracteristicas para la clasificación, entre ellas tenemos :
1.Características de BlackList: verifique si está en alguna lista negras, pueden ser utiles pero nos encontramos con los problemas de que esas direcciones ya no existen o presentan falsos negativos.
2.Características léxicas: bien sabemos que las url's tienden a parecerse bastante a las paginas originales, con pequeños cambios,ya sea usando caracteres especiales o la modificacion en la longitud de estas.
3.Características basadas en el host: cuantifican las propiedades del host del sitio web como se identifica en la parte del nombre de host de la URL y básicamente responden "dónde" está alojado el sitio, "quién" lo posee y "cómo" se administra. Se necesitan consultas de API para este tipo de características (WHOIS, registros DNS). Algunas características de ejemplo pueden ser la fecha de registro, las geolocalizaciones, el número del sistema autónomo (AS), la velocidad de conexión o el tiempo de vida (TTL).
4.Características basadas en contenido: esta es una de las familias de características menos utilizadas, ya que requiere la descarga de toda la página web, por lo tanto, la ejecución del sitio malicioso potencial, que no solo no es seguro, sino que también aumenta el costo computacional de derivando características. Las características aquí pueden estar basadas en HTML o JavaScript.
Consideraciones Previas
El aprendizaje profundo se realiza de forma iterativa, donde la función de costo se optimiza hasta una convergencia aceptable, al igual que muchos otros algoritmos de aprendizaje automático.
lote de entrenamiento es el número de datos de entrenamiento que se utilizan epoch es un paso hacia adelante y hacia atrás de "todos" los datos de entrenamiento. iteraciones son el número de pases, donde para cada pase se utiliza el número de lotes de ejemplos de entrenamiento.
Por ejemplo, para 1000 ejemplos de entrenamiento y un tamaño de lote de 500, se necesitarán 2 iteraciones para completar 1 epoch.
Base de Datos
Para el fcorrecto funcionamiento del algoritmo, la base de datos está confirmada por un 50 % Urls's benignas y 50 % Url's Malicionsas.
Esta lista de Url's se obtubo de fuentes de datos de código abierto.
Url's Benignas
El conjunto de datos contiene 21 2835 URL en total.
Observaciones
Tenga en cuenta que para entrenar mejor los clasificadores de Deep Learning se necesitan muchos más datos.
Los datos se recopilaron de fuentes abiertas o reportadas por usuarios, es decir, podrían no considerarse una muestra representativa
Las URL maliciosas tienden a cambiar con el tiempo o simplemente dejas de existir, por lo tanto, será necesaria una reentrenamiento continuo.
Prepocesamiento de la Data recién obtenida (Tokenización)
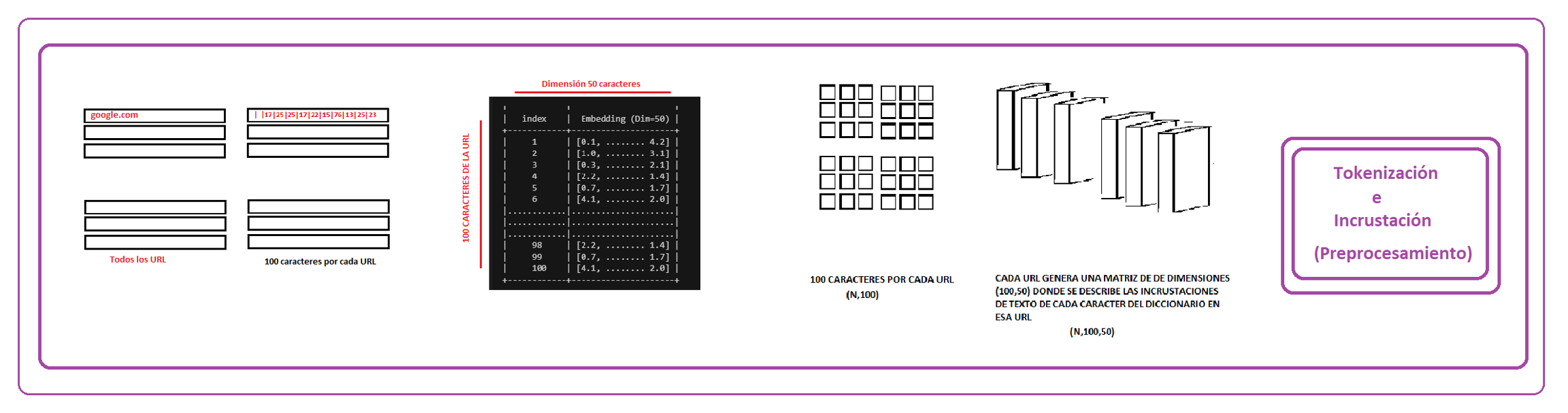
La cadena de URL sin procesar debe dividirse en "caracteres". Esto requiere construir un diccionario primero. En este caso se usara un diccionario de python para caracteres imprimibles.El cual asigna una posicion en el diccionario acorde a su codigo ASCII.

Se tomarán como restricciones que para cada URL se deben tomar como maximo 100 de estos caracteres, con ello manejamos una matriz de (m,n) donde m es la cantidad de datos y n es 100
Incrustación de Palabras :: Word2vec (Procesamiento de lenguaje Natural)
Los sistemas de procesamiento de imágenes o de video trabajan con conjuntos de datos multidimensionales muy ricos en información que se codifican como vectores. Tenemos el caso de que una imagen puede ser representados por 3 matrices, en cada una la intensidad de un color determinado por pixel, pero al tratarse de palabras, nos econtramos con el dilema que solo podemos tratarlos como valores individuales (ya sean los caracteres).
En el caso que tenemos, cada caracter es representado por un index del diccionario en python que manejamos, por ejemplo podemos relacionar la "g" con 16 y la "o" con 24 pero estas codificaciones no proporcionan información sobre las relaciones que pueden existir entre lcaracteres. Peor aún, esta representación tiene como consecuencia una dispersión de los datos importante por lo que implica que los entrenamientos necesitan más datos para ofrecer buenos modelos.
Modelo con palabras
Una forma de trabajar con esto es creando una representación vectorial de manera que por cada palabras haya una representación vectorial que indique la relaciónes de semantica entre las demás palabras, acorde a la data de entrenamiento proporcionada.
Un modelo particularmente eficiente desde el punto de vista computacional es Word2vec. Dado un conjunto de frases (también llamado corpus) el modelo analiza las palabras de cada sentencia y trata de usar cada palabra para predecir que palabras serán vecinas. Por ejemplo, a la palabra “Caperucita” le seguirá “Roja” con más probabilidad que cualquier otra palabra.
Modelo con caracteres. ¿Cómo funciona?
La finalidad de un Incruste en una Red Neuronal es mapear objetos con significado similar a puntos cercanos, con ello se pueden formar vecindades.
Para ello es necesario transforma los objetos a un espacio donde sean comparables, con ello se les puede procesar en un sistema de aprendizaje de máquina.(Por eso tokenizamos los caracteres). De esta manera es posible analizar relaciones.
En nuestro caso usaremos un incruste para obtener una medida de similaridad entre los caracteres de cada URL.
Se pueden ver relaciones interesantes de caracteres que tienden a aparecer en contextos similares.
Entradas y Salidas de las Capas de la red neuronal
La capa inicial siempre es una capa de entrada donde se define la forma de entrada inicial (aquí los 75 caracteres iniciales de la URL)
Lo siguiente es la capa word2vec, que se basa en la capa de entrada principal y es donde saldrán los caracteres importantes. Aqui es donde se iniciaran las "incrustaciones", se explicará con mas detalle en el siguiente apartado .
A partir de ahi, la formación de capaz vendrá dada por este formato
Es en la ultima capa donde se hace la clasificación, en este caso una clasificación binaria (Es o no es phishing), por ende usaremos la función de activación sigmoidea.
Arquitectura en KERAS
Después de la capa de incrustación de word2vec.Tenemos una matriz 2D de "características" para cada URL y en estos casos debemos tratar con solo una matriz resultante.
Para esto tenemos dos posibles caminos:
Primer Modelo: 1D Convolution + Fully Conected
Consiste en realizar Convoluciones con parametros diferentes y luego fusionar estos resultados utilizando la capa Fully Connected o Dense para aplanar las dimensiones del arreglo resultante.
Entrando mas a detalle, por cada url se generan 4 matrices de dimensiones (100,50), cada una es generado por una capa de convolución.Ahora, cada matriz es la entrada para capaz de activación Relu, Lambda y Dropout. La función lambda, para este código, reduce las dimensiones a un vector de longitud 256.
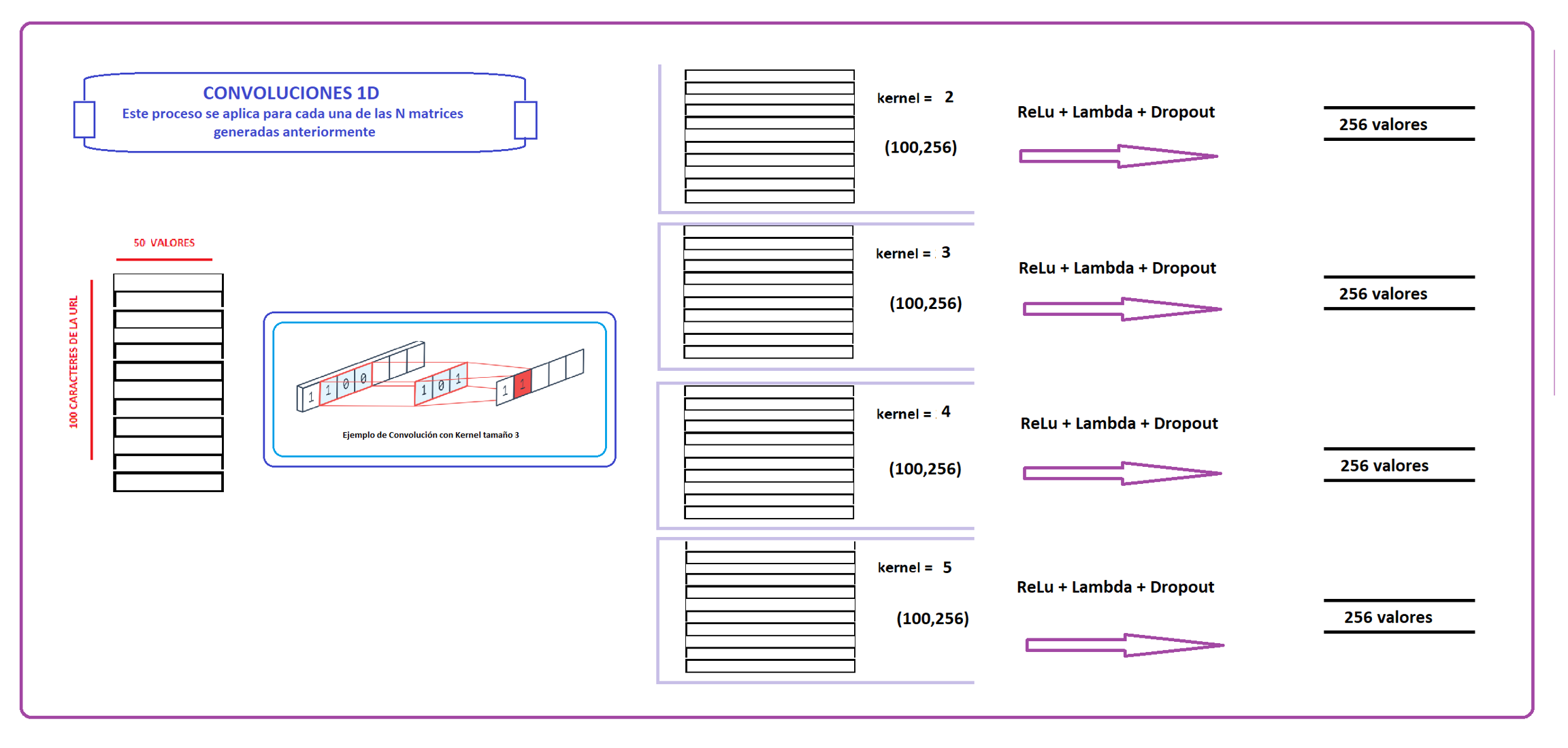
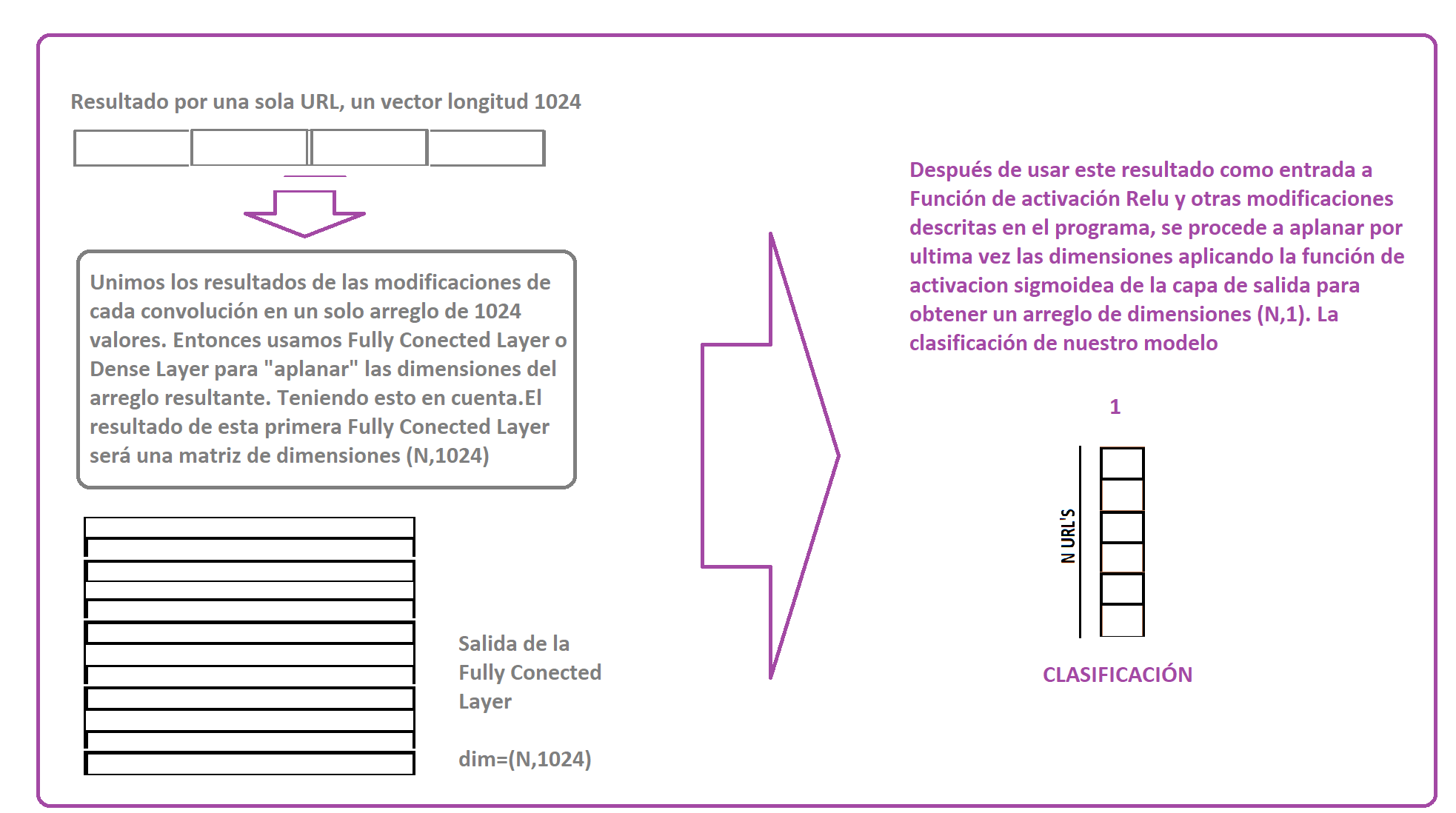
Luego de que se obtengan 4 vectores de longitud 256 correspondientes a las 4 convoluciones diferentes, estas se fusionan obteniendo un vector de longitud 1024.A este proceso es el de la capa "Fully Conected", tambien conocido como capa "Dense". Cuyo trabajo es cambiar las dimensiones *** ( aplanar) *** la matriz resultante. Despues de ello tenemos una matriz de dimensiones (N, 1024).
Esa matriz sirve como entrada para diferentes capas con función de activación Relu y modificaciones (normalizaciones.) Despues de ello, tenemos la capa de salida con función de activacion sigmoidea, la cual nos muestra las probabilidades de cada URL
Segundo Modelo: 1D Convolution + LSTM
La que consiste en capas de Convolucion 1D y para poder trabajar con los datos en 3D debemos reducirlos a 2D con la capa LSTM, a partir de ahi ya podemos usar la capa de salida con la función de activación sigmoide.
Entrando más a detalle, por cada url se generó una matriz de dimensiones (100,50), la primera capa se encargará de aplicarle filtros con un kernel de tamaño 5 con la intención de poder obtener más información a partir de los datos obtenidos.
Luego de ello (haber generado una matriz de dimensiones (100,256) por cada URL, se aplica el MaxPooling en 1D con la intención de empezar a reducir, manteniendo la información más relevantes.(Después de ello tenemos una matriz de dimensiones (25,256).
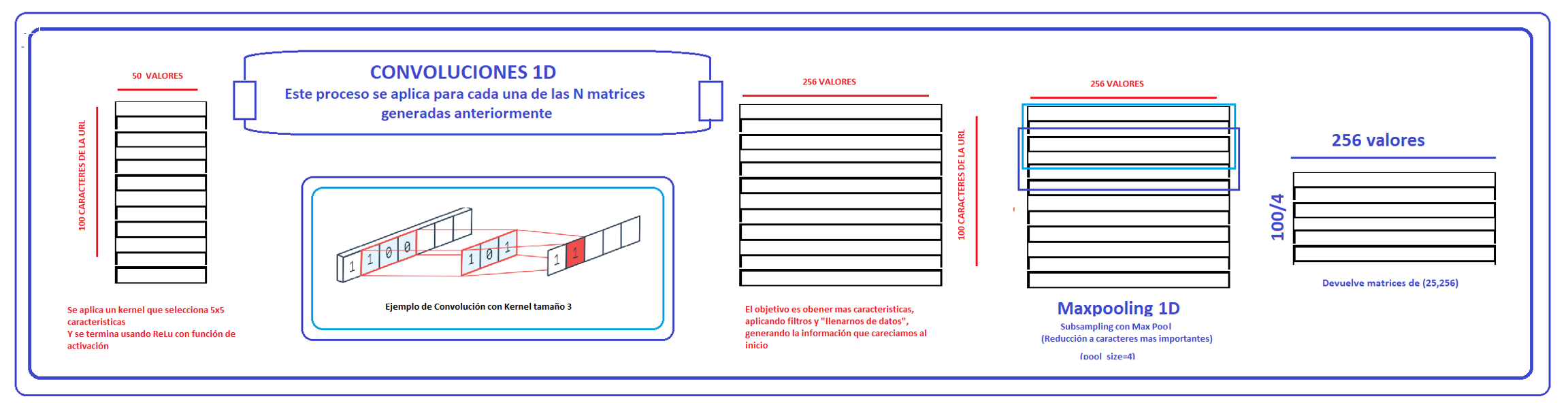
La salida de la capa Max Pooling es de una dimensión de (N,25,256) donde N es la cantidad de URL dadas para el entrenamiento.La salida de la última se utiliza como entrada para una LSTM la cual transforma la matriz (25,250) en un vector de dimensión 50, el cuál concentra la información esencial.Por ende, la salida de esta capa es una matriz de dimensiones (N,50)
Es a partir de este punto, que ya podemos pasar esta información a una capa de salida y usar la función de activación sigmoidea.

Realizando una predicción
Tokenizamos los URL que vamos a probar
Conclusiones
En cuestión de precisión, el segundo modelo (1D CONVOLUTION + LSTM) da un mejor resultado, con una precision de 94.96 %, mientras que el primer modelo (1D CONVOLUTION + FULLY CONECTED) tiene una precisión de 86.20 %
El tiempo de entrenamiento es definitivamente más largo y la precisión no necesariamente mejor en comparación con el aprendizaje automático más tradicional, sin embargo, puede generalizarse mejor a las URL maliciosas del mañana.(En especial a las que no tienen sentido)
Una de las desventajas es la deficiencia al encontrarse con nuevas palabras, lo cual es un indicador del correcto funcionamiento del modelo.
Bibliografía
word2vec
Convolucion1D
LSTM
Last updated